URL2io 产品简介
URL2Article 服务
URL2Article 用来提取并解析网页中的正文区域,实现网页正文提取、标题提取、发布日期提取、下一页链接提取等。该服务提供的 RESTful API 接口每月被调用超过6百万次。
正文提取

正文识别
精准识别网页的正文部分,提取的内容将不含有任何广告、导航和其他非正文内容。
格式转化
提取的内容可以转化为以下3种形式,默认为html形式:
html: 输出正文的 html 格式,保留包括链接、图片和其他媒体在内的所有内容。并会对内容做进一步优化,智能清除正文中的广告、清除html标签中与内容无关的相关属性等。text: 输出 txt 格式,保留正文的文字部分,并且通过智能排版引擎最大程度保留内容的排版,基本能达到和浏览器一致的排版效果。markdown: 输出 markdown 格式,保留正文的文字部分,并且通过智能排版引擎转化为 markdown 格式。raw html: 输出正文的 html 格式,原样保留原生网页的正文部分,不对内容做任何优化处理。
发布信息提取
标题识别
不是简单地通过提取<title>标签来实现,而是通过分析与正文的上下文关联来智能地识别标题,从而实现精准的正文标题提取。
发布日期识别
智能识别文章的发布日期。
惰性图片解析
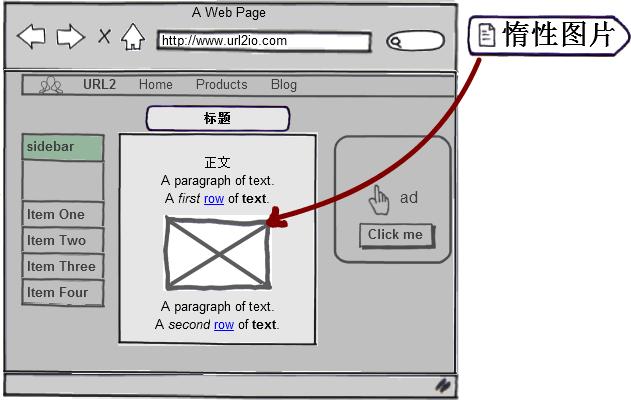
支持惰性图片解析
解决目标网页使用图片延时加载技术时,无法获取图片真实路径的问题。通过智能识别正文中的惰性图片,并自动将图片地址解析为真实地址。对于部分无法识别的图片会保留全部属性,方便开发者之后自行适配。
下一页链接提取
下一页链接识别
智能识别当前网页的下一页。如果网页的内容被分为多页,可以选择提取该网页的下一页链接从而做进一步提取。
注:这里的下一页指的是与当前页面正文内容是连续的(如一篇文章的下一部分),而不是并列的(如一篇文章后的下一篇文章)
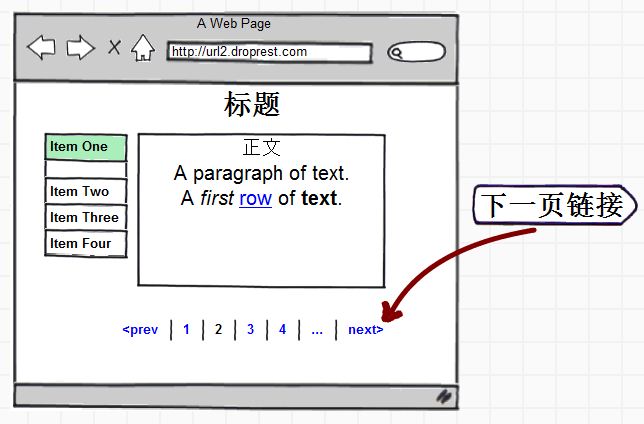
请查看 URL2Article API 使用文档 来了解如何使用。
URL2NLP 服务
文本信息智能处理
URL2NLP 用来对文本信息进行智能处理,提供中文分词、词性标注、关键词提取等功能。
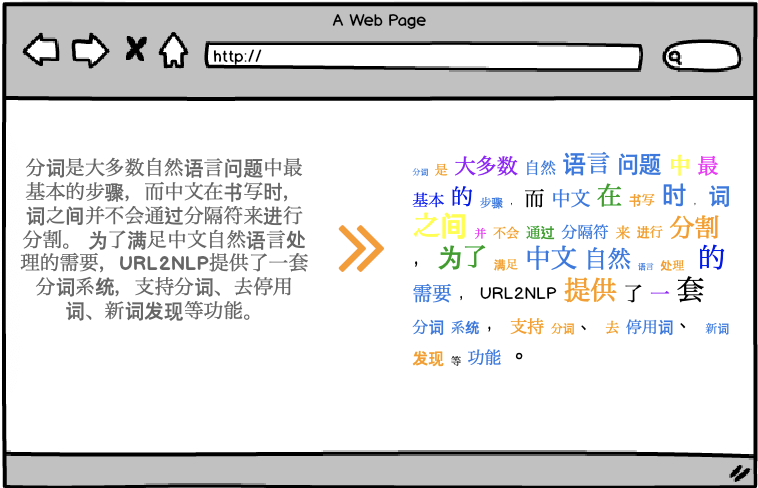
中文分词
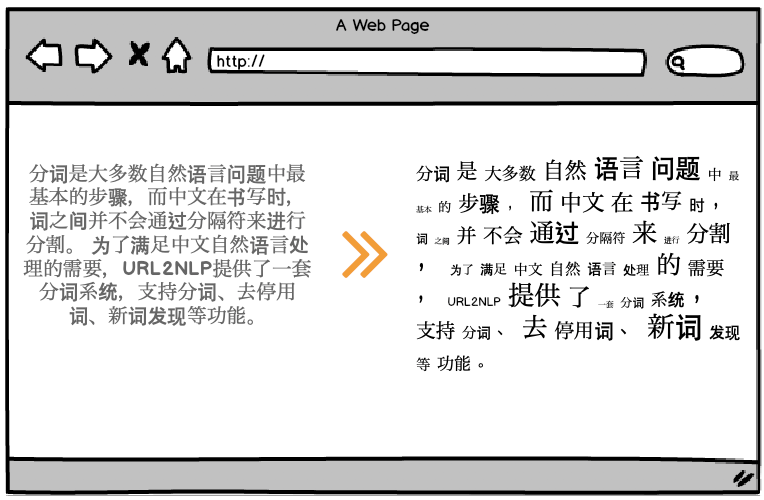
中文分词
分词是大多数自然语言问题中最基本的步骤,而中文在书写时,词之间并不会通过分隔符来进行分割。
为了满足中文自然语言处理的需要,URL2NLP提供了一套分词系统,支持中文分词、新词发现、去停用词等功能。
关键词提取
关键词提取
关键词提取引擎可以提取出文本中最有代表性的关键词,并给出对应的权重。
请查看 URL2NLP API 使用文档 来了解如何使用。
交付方式与解决方案
提供SaaS版、云镜像版、私有云版三种产品形态,覆盖各种使用场景。
三种产品形态在使用上完全一致,用户可以无缝、快速地进行切换
-
云镜像版
云镜像版(推荐)
云镜像版是将 URL2io API 镜像部署在高性能云主机上的服务方式,提供多种云主机规格,对性能配置具备更好的可控性。同时,我们会提供运维支持服务,为您免除运维烦恼。 -
私有云版
私有云版
私有云版是将 URL2io API 镜像部署在用户自有的数据中心,满足用户更高的安全合规和私密性要求。
他们正在使用 URL2io
URL2io 正在运用 AI 技术帮助更多企业,提升产品的用户体验和商业价值


Feedback